| URLs in this document have been updated. Links enclosed in {curly brackets} have been changed. If a replacement link was located, the new URL was added and the link is active; if a new site could not be identified, the broken link was removed. |
Electronic Resources Reviews
Scirus -- for Scientific Information
Science and Engineering Team Leader
USC Libraries
University of Southern California
Los Angeles, California
sarat@usc.edu
Introduction and Overview
This review is intended to both provide background on the Scirus search engine and discuss its usability. It is not an exhaustive technical review, but rather an overview that can help librarians determine if and when to use Scirus in reference and instruction environments. For this review I studied the product using several platforms: the Firefox, Internet Explorer, and Mozilla browsers on two different PC laptops running Windows XP (one professional edition, one home edition) and the Safari browser on an Apple laptop running Macintosh OS X.4 (Tiger). I have used it in other settings with other browsers and have never encountered problems.Scirus -- tagged "for scientific information only" -- is named for the Greek prophet Scirus, described by Pausanias in the ancient "The Description of Greece" (Scirus 2007a). Besides the intended prophetic link, the name clearly also implies science, and in fact some of my libraries' users have thought it meant "Science 'R' Us"! This is actually a useful mnemonic for this engine that searches for web sites, electronic journals and other document sources in science, technology and medical (STM) disciplines.
Scirus is intended for those who want to search the web -- including parts of the deeper, not freely accessible content -- for scientific information. The fact that it has won the "Best Specialty Search Engine" award from the Web Marketing Association in {2004, 2005 and 2006} helps define its niche. Elsevier does not explicitly discuss audiences on the Scirus web site, naturally hoping as many as possible will use it. I have used and recommended Elsevier's free Scirus search engine in both corporate and academic science and engineering settings. It is a good tool for both environments. In my current academic position I regularly recommend Scirus to both undergraduate and graduate students in the sciences and engineering, as well as to faculty in these disciplines, and to science and engineering librarians and library staff, at my current campus and beyond.
Launched in April 2001, Scirus was billed as {"the first comprehensive search engine dedicated to science"}. This product does a decent job of filtering out nonscientific sources in its customized crawl of over 250 million (Scirus 2007b) web, journal, and database sources. These resources are primarily from the USA and the UK, and thus in English, but STM publications from other countries are also included.
Scirus searches over 100 million .edu sites, around 25 million each of .org and .com sites, over 12 million United Kingdom academic sites, and other sources. Many of the sites have content freely available; the electronic journal articles are not typically free. In addition, the engine explicitly indexes records from a wide range of databases (Scirus 2007c). As of January 2007 it includes the following (my categorization):
- E-prints: ArXiv.org, Cogprints (open access cognitive science pre- and post-prints), IISc (India universities' e-prints), Organic E-prints (originally Danish organic farming, now international).
- Academic Institutional Repositories (IRs): Coda (Caltech's IR), CURATOR (Chiba University's IR -- Japan), Digital Archives (a combination of various American universities' IRs), DiVa (a Swedish academic IR), HKUTO and HKUST (Hong Kong University's sci-tech IR and theses), NDLTD (international open access full-text theses and dissertations), T-Space (University of Toronto's IR), WaY (Wageningen University -- Netherlands publications).
- Open Access Journals: BioMed Central, Project Euclid, Medline citations and PubMed Central articles both from PubMed, PsyDok (German and international open access psychology documents), RePEc (international open access research papers in economics).
- Commercial Journals: Crystallography Journals Online, Institute of Physics Publishing, ScienceDirect journals, Scitation-vended American Institute of Physics journals (not ASCE nor ASME journals), SIAM journals.
- Patents: Lexis-Nexis patent data.
- Technical Reports, Other: MIT's OpenCourseWare and NASA technical reports from these servers: Langley Technical Reports Server (LTRS), National Advisory Committee for Aeronautics Technical Reports Server (NACATRS), Marshall Technical Reports Server (MTRS), and Global Environmental and Earth Science Information System (GENESIS).
Scirus has been free from the beginning, and it is to be hoped it remains so, as it is a good way to find more reliable STM online resources. Scirus is also clearly linked in Elsevier's fee-based "Engineering Village 2" databases platform product. There is no additional charge for that access.
Searchability: Interface, Features and Functions
Basic Search
The product opens up to a fairly stripped down basic search (Figure 1), which by default searches input term(s) using the Boolean "or," but a selection box for "exact phrase" is provided. The default basic search display has all of the following broad categories selected in the check boxes:
- Journal sources
- Preferred web sources
- Other web sources
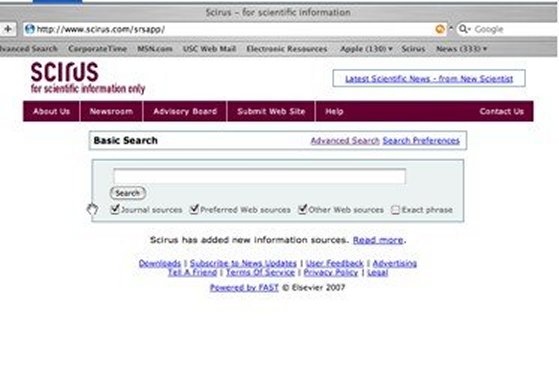
Figure 1
Journals are self-evident. "Preferred web sites" include: patents, preprints and e-prints, theses and dissertations, technical reports and documents found in institutional repositories. Everything else searched (see the bulleted list, above) is included as "Other."
One can use wildcard options, but these are not indicated on the search pages, only in the Help files (in several places). The ? character is used to replace one unknown, and the * to replace any number of unknown characters in a search input string.
Search preferences can be set from both the basic and advanced search screens, and include results per page, whether or not to open results in a new browser window, and whether or not to group ("cluster") the results by Internet domain. The preference screen with the defaults can be seen in Figure 2.
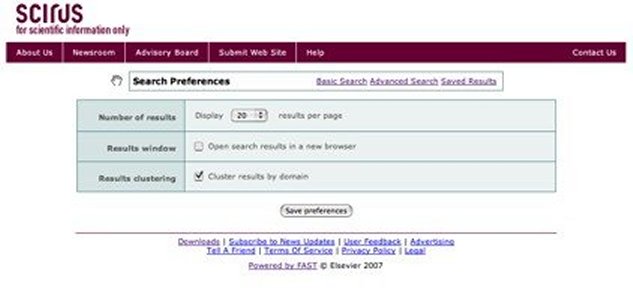
Figure 2
A link to science news stories from The New Scientist is always available at the top right of the initial search screen. There is no charge for these news pages. This is the spot in the Scirus results where advertisements appear as discussed below.
The results screen (Figure 3) is well organized and readable, and rather analogous to the ProQuest databases platform results in that all categories are displayed, but one can click on "tabs" to get the categorized sub-sets of the results (journal, preferred, other).
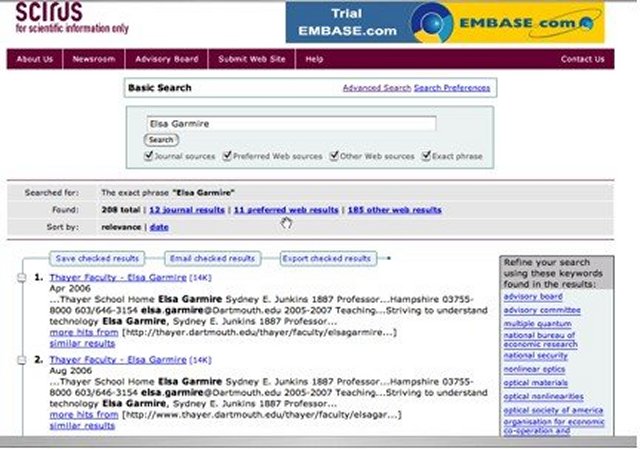
Figure 3
Search results are displayed by default in reverse chronological order (most recent at the top). The option to re-sort by relevance (based on Scirus' database coding and keywords) is also available. According to the white paper "How Scirus Works" (Scirus 2007d) and their web statement on "{ranking results}," Scirus determines relevancy in two ways:
- Location and frequency of a search term within a result account for one half of the algorithm ("static ranking") and this is known as static ranking.
- Number of links to a page -- "the more often a page is referred to by other pages, the higher it is ranked." This "dynamic ranking," is used by Google and others, an approach where "popularity" is perpetuated and thus some possibly worthwhile sites may be eliminated from search results.
As a plus, Scirus does not search document metatags, due to the well-known fact that many authors add tags designed to increase hits, not to describe the contents.
The brief record displays include both the document title as a clickable link that leads to the source, and a selection box to the left that can be clicked on to enable one to save, e-mail or export the record later. In late fall 2006, {Scirus signed an agreement} with the producers of the CrossRef open URL linking tool, so we may expect to see more options available off the title link to the source or elsewhere in the records.
Indented below the title in the results record display, the following items typically appear:
- Date of the source
- The URL (often a persistent digital object identifier or DOI for journal articles)
- Keywords and/or excerpts from the abstract
- Links to:
- More hits from the source's domain, or to
- Find similar results.
These data vary a bit, dependent upon the type of document retrieved.
Scirus results usually include an advertisement box at the top right of the screen; mainly for offers from the sources it searches. Also, Scirus now has a browser {toolbar add-in} available, an animated advertisement for which often appears in that spot. The ad feature annoyed one of my friends, a professional animator who tried the search engine at my suggestion. So, it could be a distraction for others as well, though probably not for those who frequent advertisement-heavy sites like MySpace.
Scirus also now includes some sponsored links, including book vendors such as Amazon.com and alibris as well as people-search services. These are fairly unobtrusively displayed at the bottom of results screens.
These essentially brief record displays are the only displays, unless one chooses to print, e-mail or export, in which case you can choose the citations, abstracts, keywords option for more information. See Figure 4, which shows a saved results screen, displaying both the records and options for using them further.
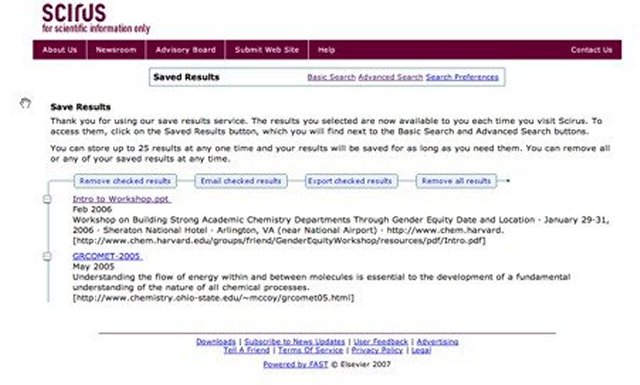
Figure 4
Options to refine the search results are listed in a column box display on the right-hand side of the screen, a similar location and layout to the refine options in Elsevier's Engineering Village 2 databases platform (see link above). The default "refine" display for the basic search is via keywords extracted from the results set, with the option to use all or any of the words, or an exact phrase. A box for adding an additional term for refinement is included (see Figure 5).
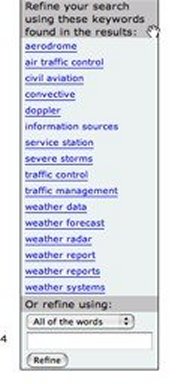
Figure 5
The links directly to scientific journals (ScienceDirect, AIP, etc., see sources list above) expand Scirus' usefulness to organizations such as large universities that subscribe to many or all of the publishers' content. Journal article results can also be resources for interlibrary loan or collection development; recurring Scirus hits to particular titles may warrant subscriptions. One of my staff at the engineering firm at which I previously worked introduced me and our other library staff member to Scirus. We then used it often as a tool when doing research for the engineers, submitting interlibrary requests for ScienceDirect journal articles retrieved. One can also immediately purchase ScienceDirect articles (accessed via Scirus or another link), usually for $30. This charge could be a source of frustration for searchers without subscriptions.
The export feature (Figure 7) has been expanded since Scirus first appeared. The two export format options are text and "RIS" -- the latter a tagged field format readable by many citation managers. For more details on RIS, see, for example, SourceForge's explanation (SourceForce 2007). For a glance at two exported records side by side in the different formats, see Figure 7.

Figure 7
A box is provided at the top of the results screen for running a new (or refined) search. In order to use a "clean" search screen (I prefer this), one must go back to the beginning by clicks; there is no direct link.
Advanced Search
The Scirus Advanced Search screen (Figure 8) presents two search string input boxes, connected only by the Boolean AND. It would be helpful if search string input were more customizable. The common "all words" (Boolean "and" links), "any of the words" (Boolean "or" links) and "exact phrase" options can be selected from a pull-down box to the left of the top input box. The default is "all words" ("anded" together) -- a nice touch that makes a search easily more specific than those done in many other metasearch engines which default to the Boolean "or" option.
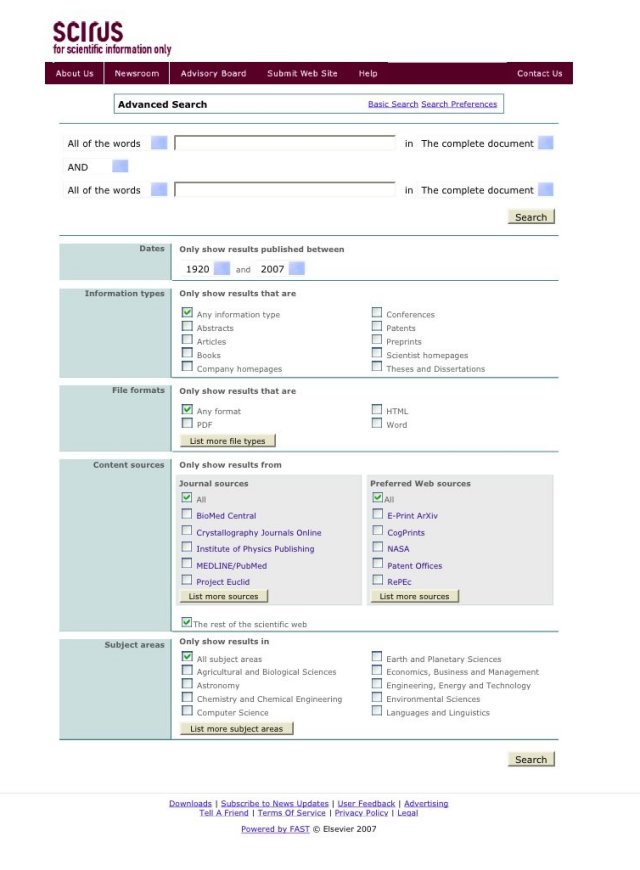
Figure 8
After each input box, one can choose the field to search via a pull-down menu. The searchable fields are:
- Complete document
- Article title
- Journal title
- Author name(s)
- Author affiliation(s)
- Keyword(s)
- ISSN
- (Part of a) URL
The affiliation and ISSN searches are particularly helpful for scientific research, and the part of a URL is an excellent feature that works well per my tests.
One can also search specific fields using field identifiers. Information on constructing such a search is available only in the Help files (see below for more on Help), but is repeated several times there. The field search option requires abbreviated tags before search terms. These are:
- Author - au:
- Title - ti:
- Journal - jo:
- Keywords - ke:
- URL - url:
- Domain name - dom:
- Author affiliation(s) - af
The remaining search refinement options are in a two-column display, boxed-in part. All the Scirus screens are geometric in layout, and easy to read. This advanced search screen is particularly pleasing, with plenty of white space. The only possible drawback is that it covers two browser screens on all of the options utilized for this review -- Firefox, Mozilla, and Internet Explorer, in Windows XP and Safari in Mac OS X. The refinement options include: date range, information types, file formats, content sources (discussed in the introduction section of this review) and subject areas. File formats, content sources and subject areas all display some of the options by default, with a "list more" button to display them all. Several of the more interesting options are highlighted below.
Information types: ten options are available via check boxes -- abstracts, articles, books, company home pages, conference, patents, preprints, scientist home pages, theses and dissertations or any/all. The company and scientist home pages are an unusual and welcome search refinement feature that seems to work fairly well. A search for string theorist "Clifford Johnson" yielded 15 results, the majority of which were the correct person, with his USC physics faculty home page appearing as result #1. Several of the results were for sources discussing or by people with names that included the phrase "Clifford Johnson," so the retrieval was accurate, though not the person for whom I was searching. Scirus did NOT find the physicist Clifford Johnson's two blogs directly, however, only some mentions of them on other web pages. It does not currently search blogs as thoroughly as the Technorati blog tracker or the Google blog search function.
File formats: the options are HTML, PDF, Word, PPT, PS, TeX and any/all. Postscript and TeX are especially useful in a scientific search engine as many e-prints are still available in these formats developed by physicists and other scientists.
Subject areas: Scirus uses "linguistical analysis" to assign documents to subject categories. This function is part of the FAST search platform (more details below). The subjects are grouped into 21 discipline categories:
- Agricultural and Biological Sciences
- Astronomy
- Chemistry and Chemical Engineering
- Computer Science
- Earth and Planetary Sciences
- Economics, Business and Management
- Engineering
- Energy and Technology
- Environmental Sciences
- Languages and Linguistics
- Law
- Life Sciences
- Materials Science
- Mathematics
- Medicine
- Neuroscience
- Pharmacology
- Physics
- Psychology
- Social and Behavioral Sciences
- Sociology
Scirus is a bit more precise on physical sciences searches, as evidenced by these subject categories. To search life sciences, one would need to select agricultural/biological and life science and medicine and neuroscience, and perhaps also pharmacology, to be sure to be comprehensive while excluding physical sciences and other disciplines.
Help Functions
The Scirus Help files can always be accessed from the menu bar that appears near the top of each screen. It is not contextualized; a click on help always goes to the top level of the files (the URL is hidden). This means it can take several clicks to get to the information desired, a minor inconvenience.Help is organized in four categories with sub-pages within each: Search Tips, Tools, Legal and General. See Figure 9 for a screen shot of the Search section of Help. Some of the information is repeated across help files, e.g., information on wildcard options is in both the general as well as the advanced search sections, but this is more helpful than not.
Figure 9
Technical Details and Additional Features
Technical
The white paper "How Scirus Works" (Scirus 2007d) describes in some detail the FASTTM search technology upon which Scirus is based. Fast Search, headquartered in Oslo, Norway, develops customized enterprise and other search products. Some of the FAST proprietary approaches to web searching discussed in the white paper are summarized conceptually below. Scirus is not the only database familiar to librarians that is built with this company's products: the Factiva database platform also employs FAST technology.Briefly, Scirus web crawls (done by a "farm" of machines) are based upon a "seed list" of URLs that are manually checked for relevance before inclusion on the list. In other words, humans are filtering the input source for the web crawler. In addition, the databases of the partners (described in the review of sources, above) are included in the overall knowledge base; these databases have already been vetted. Open Access Initiative (OAI) resources such as preprints archives are also harvested for the Scirus content, but only those of a scientific or technical nature. I think this filtering by experts near the beginning of the process is a key reason for the success of Scirus as a scientific search engine.
A separate knowledge base is maintained for the keywords, and is compiled and checked in part against a variety of discipline-specific dictionaries; a list of these does not appear to be available. The linguistical analysis is the basis for the relevancy ranking; both words and phrases are utilized, in a process that is partially automated and partially manual.
The structure of a page is considered for the classification of the resource into the subject categories. The white paper gives a good example of this process on page 11:
"For instance, scientist homepages can be recognised by looking at structural information -- such as the presence of address information, biographical data layout, publication lists -- and by the presence of keywords like 'homepage', 'publication list' etc."
"Intelligent query rewrites" help ensure relevant results, and include variations on quotes and even on spelling. This feature is especially helpful given that European content (e.g., "recognized" in the excerpt above uses the British English "s" rather than the American English "z") is prevalent in the sources.
The white paper goes into a great deal of detail, and Elsevier is to be commended for making it available. It is periodically updated. For those that want to know more about the search engine construction, please see the paper, Also, more information is available at the Fast Search site (FastSearch 2007). A few practical technical details about accessing Scirus follow.
Access
Java and JavaScript must be enabled on one's browser in order to use Scirus. I have found it to display and work equally well on the platforms used for this research: Windows XP OS -- Internet Explorer, Firefox and Mozilla browsers; and Mac OS X: Safari browser.As noted in the detailed Scirus Privacy Policy, which is available via a link in the footer of every page (the specific URL is hidden), the search engine uses both session and persistent cookies. Session cookies are used to customize search results, which can be noticeable if one runs a number of searches. They are deleted when the browser is closed.
Persistent cookies are used for the "save search results" function. Unfortunately Scirus does not currently allow one to create an account so that results could be accessed from different computers.
Scirus now provides a plug-in for the Firefox browser that is usable on multiple platforms, and customizes Firefox searches toward Scirus. It can be downloaded from the "{Installing and using the Scirus Firefox search plugin}" page. Innumerable search engines provide similar browser tools. I do not find them useful, but some of the student assistants in our library (mostly engineering or science graduate students) regularly install a variety of them on the reference and circulation workstations, so this feature is useful to some.
Additional points
One can submit a web site to be included in Scirus searches, via their "{Submit a Web site to Scirus}" page. The reviewers of submissions are not specifically cited. However, Scirus does have an Advisory Board comprised of Library, Scientific and Technical Boards. Members' contact information is listed on the {Board page}, easily accessed from the link in the header bar on each page.Scirus News Updates are available by e-mail, with the completion of a simple subscription form. RSS feeds are not directly available from Scirus at this time (January 2007), but I would not be surprised to see this export capability in the near future.
There are not many free, multidisciplinary scientific search engines extant. (Discipline(s)-specific search engines are sometimes termed "vertical" or "domain" search engines, though the latter term can be confusing, implying only one Internet domain as the search subject. These are some of Scirus' closest challengers:
- The scientific search engine from Bielefeld University (Germany), BASE, for Bielefeld Academic Search Engine, went live in 2005, but was only publicized in the US in 2006. It too uses the FAST search technology. BASE harvests open access metadata from scientific information repositories, including BioMed Central and a number of university repositories in Dspace format. BASE is worth watching.
- OJOSE (Online JOurnal Search Engine), developed and maintained by Romain Lanners, a University of Freiburg (Switzerland) professor, is free and fairly comprehensive, but the display is very "busy" and a bit confusing to use.
- SciSeek, is freely accessible but is a profit-making venture and does not search as many free, scholarly sites as Scirus.
- Search4Science.com, the most direct competitor to Scirus, is apparently now defunct. It was created by Oslo, Norway researchers and expanded in partnership with Northern Light Technology, using their search Dynamic Search technology
As Google Scholar's capabilities expand, it may become more of a competitor for Scirus. However a searcher would logically need to limit search terms in Scholar to get the scientific-only results for which Scirus already filters.
Conclusion
Scirus does indeed live up to its stated objectives:
- "Pinpoint scientific, scholarly, technical and medical data on the web.
- Find the latest reports, peer-reviewed articles, patents, pre prints and journals that other search engines miss.
- Offer unique functionalities designed for scientists and researchers."
In addition, Elsevier routinely updates and expands the capabilities of Scirus, mostly for users' benefit, such as the recent partnership with CrossRef, which should augment search result linking and manipulation capabilities.
Scirus is a useful meta (or vertical, if you like) search engine for scientific topics, and the inclusion of ScienceDirect and other, especially physics, electronic journals makes it a viable alternative to the perennially popular Google which is often not the best choice for research browsing. I have used Scirus and its sources to successfully demonstrate to university students in library instruction sessions the importance of accessing reliable sources. I plan to continue to strongly recommend Scirus to the students, faculty and staff in science and engineering for whom my library team and I provide instruction, reference and research services. I hope Elsevier continues to provide this tool for free!
References
Fast Search. [Online]. Available: http://www.fastsearch.com/ [Accessed January 2007].Scirus. 2007a. About Us. [Online]. Available: {http://www.scirus.com/srsapp/aboutus/} [Accessed January 2007].
______. 2007b. About Us. Pinpointing Scientific Information. [Online]. Available: {http://www.scirus.com/srsapp/aboutus/#point} [Accessed January 2007].
______. 2007c. About Us. The Range of Scientific Content Scirus Covers. [Online]. Available: {http://www.scirus.com/srsapp/aboutus/#range} [Accessed January 2007].
______. 2007d. How Scirus Works. [Online]. Available: {http://www.scirus.com/press/pdf/WhitePaper_Scirus.pdf} [accessed January 2007].
SourceForge, Chapter 7. Data input. [Online]. Available: http://refdb.sourceforge.net/manual-0.9.4/c2166.html [accessed January 2007].
Additional Reading
O'Leary, Mick. 2006. Scirus Blends Public, Private STM Realms. Information Today 23(3):41-42.
| Previous | Contents | Next |
