Text Analysis of Chemistry Thesis and Dissertation Titles
Vincent F. Scalfani
The University of Alabama Libraries
Tuscaloosa, Alabama
vfscalfani@ua.edu
Abstract
Programmatic text analysis can be used to understand patterns and reveal trends in data that would otherwise be difficult or impossible to uncover with manual coding methods. This work uses programmatic text analysis, specifically term frequency counts, to study nearly 10,000 chemistry thesis and dissertation titles from 1911-2015. The thesis and dissertation titles were collected from nine major research universities across the southeastern United States. The libraries of all nine are members of the Association of Southeastern Research Libraries (ASERL). Text analysis scripts were written in both MATLAB and Mathematica and used to extract the most common words and phrases from the titles. Some of the most common terms appearing in chemistry thesis and dissertation titles included synthesis, spectra, reaction, application, mass spectra, and nuclear magnetic resonance. Word usage over time was studied and used to reveal general research trends in chemistry. All data, programming scripts, and instruction methods are provided openly to the community. This article will be of interest to researchers and librarians interested in text analysis and chemistry research trends.
Introduction and Literature Review
Theses and dissertations offer a representative view into the research conducted at an institution, arguably more so than journal articles. For example, some researchers estimate that 80% of chemistry research is never published in peer-reviewed journal articles, leaving the majority of work hidden in laboratory notebooks, presentations, summary reports, and theses and dissertations (de Laet et al. 2000; Downing et al. 2010; Stoye 2015). Content within theses and dissertations is also more comprehensive compared to the selected content chosen for peer-reviewed publication. As such, it is not surprising that library science researchers have spent a great deal of time analyzing university theses and dissertations, most often through citation analysis (Hoffmann and Doucette 2012). These analyses examine parameters of the citations relative to the local collections. Researchers combine citation data such as type, age, frequency, subject area, and publisher with other library assessment parameters such as usage statistics (Wical and Vandenbark 2015) or cost (Chrzastowski 1991) and use them to assess current collections, understand research trends, as well as inform future collection development decisions. Several recent citation analysis articles study chemistry thesis and dissertation citations (Gooden 2001; Sudhier and Kumar 2010; Vallmitjana and Sabaté 2008; Zhang 2013).
Another interesting method of evaluating thesis and dissertation research is title analysis, which studies the characteristics of the title such as topical subject area, frequency of terms used, co-word occurrence, and number and type of words used. These studies most often focus on journal article titles to determine research trends (Callon et al. 1991; Cantrill 2015; Maiti and Dutta 2013; Milojevic et al. 2011; Xie et al. 2008); relationship to citation counts (Jamali and Nikzad 2011; Letchford et al. 2015); and relevance to article content (Maiti and Dutta 2013; Resnick 1961; Tocatlian 1970; Windsor 1971). A handful of title analysis studies in the literature are related to theses and dissertations (Danton 1959; Finlay et al. 2012; Keller 1992; Loomis 1985; Newberry 1978; Rodriguez and Moreiro 1996; Sugimoto et al. 2011).
For example, in an effort to improve cataloging efficiency, Keller (1992) studied Masters theses title words at Indiana State University to determine how often there is a match between a title word and subject heading. Loomis (1985) studied doctoral nursing program research trends from 1976-1982 by analyzing nursing dissertation abstracts and titles from 20 institutions. Rodriguez and Moreiro (1996) studied ecology dissertation titles from Spain and Spanish-speaking Caribbean countries from 1976-1993 to evaluate the growth of the research in these countries, using total word counts and number of informative words in the dissertation titles as a measure to evaluate the complexity of ecology research.
Lastly, there are a few studies of library science dissertation titles. Danton (1959) evaluated library science dissertation titles and manually classified the dissertations into subject areas based on the title descriptions. Later, Newberry (1978) followed up with a similar approach of manually classifying library science dissertations into unique subject areas to reveal trends in library science research over time. More recently, Sugimoto et al. (2011) used natural language processing algorithms to programmatically classify library science dissertation titles/abstracts into subject areas and determine the frequency of informative words used. Finlay et al. (2012) expanded on this work to study the occurrence and frequency of words in library science dissertation titles and abstracts that are representative of curriculum topics taught in Master of Library Science programs.
Among the above studies on dissertation title analyses, only Sugimoto et al. (2011) used a programmatic text analysis approach to study the titles. This is surprising, given the potential use of automated text analysis methods and recent interest in data mining (Link et al. 2015; Siguenza-Guzman et al. 2015), text mining (Nagarkar and Kumbhar 2015), and data visualization in libraries (Finch and Flenner 2016; Haren 2014; Murphy 2015). Moreover, no one has yet published a title analysis study on chemistry theses and dissertations.
This article seeks to fill this gap in the literature by using a programmatic text analysis approach to study almost 10,000 chemistry thesis and dissertation titles published between 1911 and 2015. The chemistry theses and dissertations were selected from nine major research institutions, whose libraries are members of the Association of Southeastern Research Libraries (ASERL). The selected dataset was convenient to acquire and provided a manageable subset of chemistry thesis and dissertation titles. In this article, I present an analysis and discussion of the results related to discovered research trends. All data, programmatic text analysis code, and instructions for executing code are available openly to the community with minimal restrictions for researchers interested in reproducing the results or investigating similar text analysis research questions.
Hypothesis
Text analysis, including word and phrase frequency, of chemistry thesis and dissertation titles can help librarians understand chemistry research trends.
Methods
Collection of Chemistry Thesis and Dissertation Titles
The author collected Chemistry Department thesis and dissertation bibliographic records from nine major research universities, including: Duke University (Duke), Emory University (Emory), Louisiana State University (LSU), The University of Alabama (UA), University of Florida (UF), University of Georgia (UGA), University of Kentucky (UK), University of Mississippi (UM), and University of South Carolina (USC). The dataset includes two private universities (Duke and Emory) and seven public universities across eight southeastern states. Chemistry theses and dissertations were defined as any dissertation or thesis submitted and subsequently accepted to the university's Chemistry Department, including those incorporating biochemistry programs.
The author gathered chemistry thesis and dissertation bibliographic data via two different approaches. Whenever possible, the bibliographic records were discovered at the institution's library catalog or discovery service and then bulk-exported as an EndNote-compatible file format (e.g. RIS). In cases where that was not possible, an alternative approach used an Endnote Connection File (Thomson Reuters 2016) to search the institution's library catalog within Endnote X7.3 and batch-collect the bibliographic records.
I imported and saved records into an Endnote X7.3 database library, removed duplicates, and manually corrected inconsistencies such as an author name appearing in the title or a missing year. I then created a custom output style that displayed only the title of the bibliographic records and exported the titles as UTF-8 text files within the desired year ranges. These files were then converted to ANSI encoding before analysis.
Text Analysis of Chemistry Thesis and Dissertation Titles
I performed text analysis with MathWorks MATLAB R2017a and Wolfram Mathematica 11.0.1. In MATLAB, I wrote a custom script based on work in Text Mining with MATLAB (Banchs 2013). The MATLAB script written for this article, matlab_TI_analysis, first imported and normalized a text file of words. This normalization step converts text to lowercase, eliminates extra blanks, removes non-alphanumeric characters, and removes non-descriptive and stop words from a custom created dictionary. This dictionary includes words that are commonly found in dissertation and thesis titles, but do not contribute significantly to the overall meaning such as "the", "a", "part I", "part II", and "study." Variations of common chemistry words having similar meaning were combined. For example, synthesis* = synthesis, synthetic, syntheses, biosynthesis, biosynthetic, and synthetically. A full list of stop words and combined words is in the script code (see Appendix). An asterisk in this article indicates that a word contains multiple similar variations. After normalizing the text, the script sorts and counts the words and displays a list of the most common 100 words (unigrams) and their corresponding frequency.
I wrote a similar script in Wolfram Mathematica 11.0.1, mathematica_TI_analysis, which executes analogously to the matlab_TI_analysis script. A pre-processing step normalizes the text and then displays the most common 100 unigram words along with their frequency of occurrence. I added an additional analysis step in Mathematica that displays the frequency of words, including bigrams and trigrams (two and three words in a continuous sequence). Mathematica also generates a simple word cloud visualization from the most common 100 unigram words. Other data plots were created in OriginPro 2016 and exported as .png files for this article. The data used for the normalized frequency vs. year plots were binned (averaged) at five year intervals in an effort to smooth the data and reveal trends. The normalized frequency represents the yearly frequency divided by the number of thesis and dissertation records for the corresponding year. Dividing each frequency by the corresponding yearly number of records prevents the observation of artificial trends simply due to a higher or lower number of titles in a given year. All data, programmatic code and detailed instructions for executing the code in MATLAB and Mathematica are available in the Appendix. New users of MATLAB and Mathematica can execute the code with minimal time investment.
Results and Discussion
Overview of Chemistry Thesis and Dissertation Titles
The total number of chemistry thesis and dissertation bibliographic records collected from the nine southeastern universities was 9684 from years 1911 to 2015 (Table 1).
Table 1. Overview of collected chemistry thesis and dissertation bibliographic records from nine ASERL Institutions.
| University | Abbreviation | Years | # of Chemistry Theses and Dissertations |
|---|---|---|---|
| Duke University | Duke | 1928-2015 | 1,221 |
| Emory University | Emory | 1923-2015 | 974 |
| Louisiana State University | LSU | 1913-2014 | 1,130 |
| The University of Alabama | UA | 1924-2015 | 658 |
| University of Florida | UF | 1913-2015 | 2,290 |
| University of Georgia | UGA | 1932-2015 | 1,232 |
| University of Kentucky | UK | 1914-2015 | 734 |
| University of Mississippi | UM | 1929-2015 | 267 |
| University of South Carolina | USC | 1911-2015 | 1,178 |
| Total | 9,684 | ||
It was not possible to use a thesis and dissertation database such as ProQuest Dissertations & Theses. Advanced searches within the ProQuest database limiting by university and department retrieved many fewer results than those discovered directly in the university library catalogs. This is likely due to incomplete submission of theses and dissertations to ProQuest and/or inconsistent indexing.
The author made efforts to collect all discoverable thesis and dissertation bibliographic records by taking into account different cataloging practices. It was necessary to first learn how theses and dissertations are cataloged at each university, and then strategically execute and combine searches to locate all of the cataloged chemistry department theses and dissertations. The Endnote Connection file search used a similar approach. For example, the chemistry theses and dissertations in the UM Library Catalog are found under the author "University of Mississippi Department of Chemistry" and "University of Mississippi Department of Chemistry and Biochemistry," a likely result of a departmental name change. Additionally, the theses and dissertations at UM have different subject headings, denoting either a thesis or a dissertation. Another example: the Duke Library Catalog lists chemistry dissertations under the author heading "Duke University. Department of Chemistry." as well as the abbreviated form "Duke University. Dept. of Chemistry." It is possible that the searches missed some records either due to cataloging inconsistencies, lack of cataloging, or lack of discoverability. This is definitely the case for some recent theses and dissertations as there can be a delay from the time of submission to appearance in the library catalog. Despite these limitations, I collected the great majority of the bibliographic records and am confident they are representative of the intended dataset.
Figure 1 depicts the total number of chemistry theses and dissertation records collected from all nine southeastern universities listed in Table 1. The plot omits 2015 due to an artificially low number of bibliographic records from that year, likely a result of cataloging delays. In the early 1900s, only a handful of advanced chemistry degrees were awarded, while presently approximately 200 are awarded per year across the nine ASERL universities (assuming each thesis and dissertation is one successful graduate student).
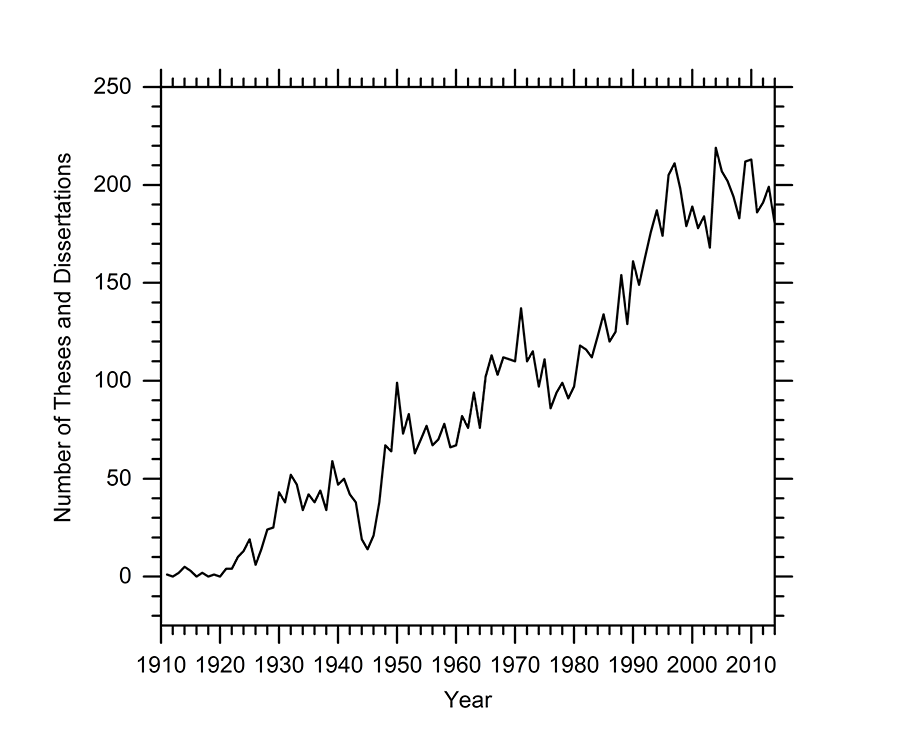
Figure 1. Number of chemistry thesis and dissertation bibliographic records collected from Duke, Emory, LSU, UA, UF, UGA, UK, UM, and USC from 1911-2014 showing a steady, nearly linear, increase of completed chemistry thesis and dissertations.
Text Analysis of Chemistry Thesis and Dissertations Titles - Script Performance
The 9,684 titles included a total of 115,008 words and 12,886 unique words (excluding some non-descriptive words and variations of the same word). The majority of the text analysis was performed with MATLAB, using the custom matlab_TI_analysis script. In order to verify the programmatic methods used within MATLAB were producing what was expected, I wrote a similar script, mathematica_TI_analysis, independently in Mathematica. In a comparison test of the two scripts generating the 100 most common unigram words and their respective frequencies from the same dataset, the two scripts produced nearly identical results with 100 out of the 100 words matching and 98 out of the 100 words with the same frequency. Only two words were off by one count (e.g., in MATLAB catalysis* occurs 389 times, while in Mathematica, it occurs 388 times). This minor discrepancy had no observable impact on the overall results. Both scripts were efficient and easy to deploy. Total analysis run time was about 20 seconds or less in MATLAB or Mathematica to process 100,000 words.
One limitation of the scripts is that only a finite number of words were recorded in the results, in most cases limited to the top 100 most common words. As a result, if a particular word of interest has a very low frequency (e.g., only appears once in the dataset), this word might not appear in the word list and will not be counted. Since this only occurs for instances with low frequency, it has no measurable effect on any of the overall results and conclusions in this study. Further, while I made efforts to combine all similar words, it was not possible to account for all variations. For example, the term polymer* includes: polymer, polymers, copolymer, polymeric, poly, polymerization, and polycondensation. If the title included a different variation or a specific name of a polymer, it would not be counted unless the author specifically wrote the polymer name with the prefix poly separated from the word (e.g., poly(styrene), not polystyrene).. Combining variations of similar words can also be limiting without knowing the related context of neighboring words. As an example, I chose to combine the words spectroscopy and spectrometry into spectra*. While both spectroscopy and spectrometry are related terms, there can be significant differences in their usage (International Union of Pure and Applied Chemistry 2016). A more comprehensive dictionary or the use of advanced chemical text mining tools (Gurulingappa et al. 2013) may be able to overcome these limitations in the future.
Another potential limitation to these scripts is that the custom dictionary of non-descriptive stop words and combined words is optimized for chemistry title datasets. More generic non-descriptive stop word removal and stemming algorithms (Porter 2006) were tested and found not to perform well with the highly discipline-specific terminology. However, the syntax code in both MATLAB and Mathematica is adaptable. Users can add or replace words directly within the code. Moreover, the code will still execute regardless of whether the custom dictionary words appear in the input text dataset. The request to either delete a word or combine words defined in the dictionary will be ignored. As such, both the matlab_TI_analysis and mathematica_TI_analysis scripts can be easily adapted for text analysis work outside the field of chemistry and librarianship (Appendix).
Text Analysis of Chemistry Thesis and Dissertations Titles - Overall Trends
Table 2 and Figure 2 summarize the most common words from the entire dataset of 9684 chemistry thesis and dissertation titles from nine different ASERL institutions.
Table 2. Ten most common words (unigram). Asterisk indicates a combination of similar variations of the word.
| Rank | Word (unigram) | Frequency |
|---|---|---|
| 1 | synthesis* | 1,766 |
| 2 | spectra* | 1,040 |
| 3 | reaction* | 754 |
| 4 | application* | 590 |
| 5 | complex* | 574 |
| 6 | characterization* | 571 |
| 7 | acid* | 491 |
| 8 | metal* | 488 |
| 9 | compound* | 466 |
| 10 | polymer* | 465 |

Figure 2. Word cloud of common words. Larger words indicate a higher occurrence frequency.
Synthesis* and spectra* are by far the most frequently occurring words in chemistry thesis and dissertation titles within the studied dataset. Combined, these words were present in approximately 30% of the titles. Reaction*, application*, complex* or characterization* appeared in 26% of the titles. Acid*, metal*, compound*, or polymer* was present in 20% of the chemistry titles. The word cloud in Figure 2 depicts the top 100 words with their sizes relative to frequency. Other important and common words not in the top 10 are shown in the word cloud such as catalysis*, molecular, ion*, DNA, and structure.
Table 3 summarizes the top ten phrases of bigram and trigram words. This analysis revealed important and popular chemistry instrumental characterization techniques. For example, in the bigram analysis, technique-related word pairs included: mass spectra*, magnetic resonance, nuclear magnetic, and gas chromatography. In the trigram analysis, eight out of the top ten most frequent trigrams were related to instrumental characterization techniques such as nuclear magnetic resonance, tandem mass spectra*, and electron paramagnetic resonance.
Table 3. Ten most common words (bigram and trigram). Asterisk indicates similar variations of the word were combined.
| Rank | Word (bigram) | Frequency | Word (trigram) | Frequency |
|---|---|---|---|---|
| 1 | mass spectra* | 249 | nuclear magnetic resonance | 92 |
| 2 | synthesis* characterization* | 184 | transition metal* complex* | 36 |
| 3 | transition metal* | 138 | magnetic resonance spectra* | 36 |
| 4 | magnetic resonance | 117 | laser desorption ionization | 31 |
| 5 | total synthesis* | 114 | tandem mass spectra* | 30 |
| 6 | nuclear magnetic | 98 | chromatography mass spectra* | 30 |
| 7 | metal* complex* | 77 | electron paramagnetic resonance | 29 |
| 8 | gas chromatography | 71 | fourier transform infrared | 26 |
| 9 | amino acid* | 70 | magnetic circular dichroism | 25 |
| 10 | design synthesis* | 68 | laser induced breakdown | 25 |
In an effort to understand how chemistry research has changed over time, the dataset was separated into five different time intervals that largely correspond to major historical social, conflict, and economic factors in American history (e.g., WWI, Great Depression, WWII). Such historical events are likely to impact the direction of scientific research (Whitesides 2015). The intervals selected for this analysis were 1911-1945, 1946-1964, 1965-1980, 1981-1991, and 1992-2015. The top five unigram words for each interval are presented in Table 4.
Table 4. Five most common words (unigram) by historic era. Asterisk indicates a combination of similar variations of the word.
| Rank | 1911-1945 | 1946-1964 | 1965-1980 | 1981-1991 | 1992-2015 |
|---|---|---|---|---|---|
| 1 | preparation* | reaction* | synthesis* | synthesis* | synthesis* |
| 2 | reaction* | synthesis* | spectra* | spectra* | spectra* |
| 3 | acid* | compound* | reaction* | complex* | application* |
| 4 | certain | acid* | complex* | characterization* | characterization* |
| 5 | derivative* | derivative* | compound* | reaction* | polymer* |
There are several interesting trends here. From 1911-1964, the words preparation* and reaction* are favored over synthesis*. This is likely a result of a change in vocabulary preference, not a significant change in meaning or research area. Preparation, reaction, and synthesis are all broad terms that can often be interchanged to have similar meaning. Further, in the 1911-1945 and 1946-1964 time periods, research on acids and creating derivatives of substances was very popular (a derivative of a substance is a modification to a parent compound). After 1964, spectra, characterization techniques, and research on complexes1 are favored over acid and derivative research. Another significant change occurs in the 1992-2015 interval, where complex* and reaction* are replaced with application* and polymer* in the top five.
Similar trends of chemistry words were observed in an earlier analysis of the Journal of American Chemical Society (JACS) article titles from 1900-2014 (Cantrill 2015). Cantrill analyzed the most frequent words appearing in over 168,000 JACS titles by decade. Similarities exist in the data analysis of the JACS article titles and the nine ASERL university chemistry thesis and dissertation titles. For example, in the JACS article titles, Cantrill found that there was an emphasis on the words acid, derivatives, and preparation in the early to mid-1900s. By 1960, synthesis, spectroscopy-related terms, and complexes became more prominent, agreeing with the thesis and dissertation title analysis results reported here. Differences do exist: In the JACS article titles, the words polymer or application do not occur as frequently, which is likely a reflection of the journal's scope.
Figures 3 and 4 plot the yearly frequency from 1925-2015 of 13 selected words from the nine ASERL university chemistry thesis and dissertation titles. Synthesis* increased dramatically from around 1968 to 1980, and then remained about the same frequency since 1980. Preparation* and acid* decreased steadily from 1925 to 2015. Spectra* increased significantly from 1942 to 1974, and then again from 1982 to 1990, before decreasing in frequency. Characterization* saw a steady increase in frequency from 1964 to 2015, while reaction*, analysis, determination, and properties have all stayed relatively consistent in frequency since 1925. Application* and nano* saw dramatic increases in frequency starting in 1968 and 1998, respectively. And lastly, catalysis* and polymer* have increased gradually from 1960 to 2015 (Figures 3 and 4).
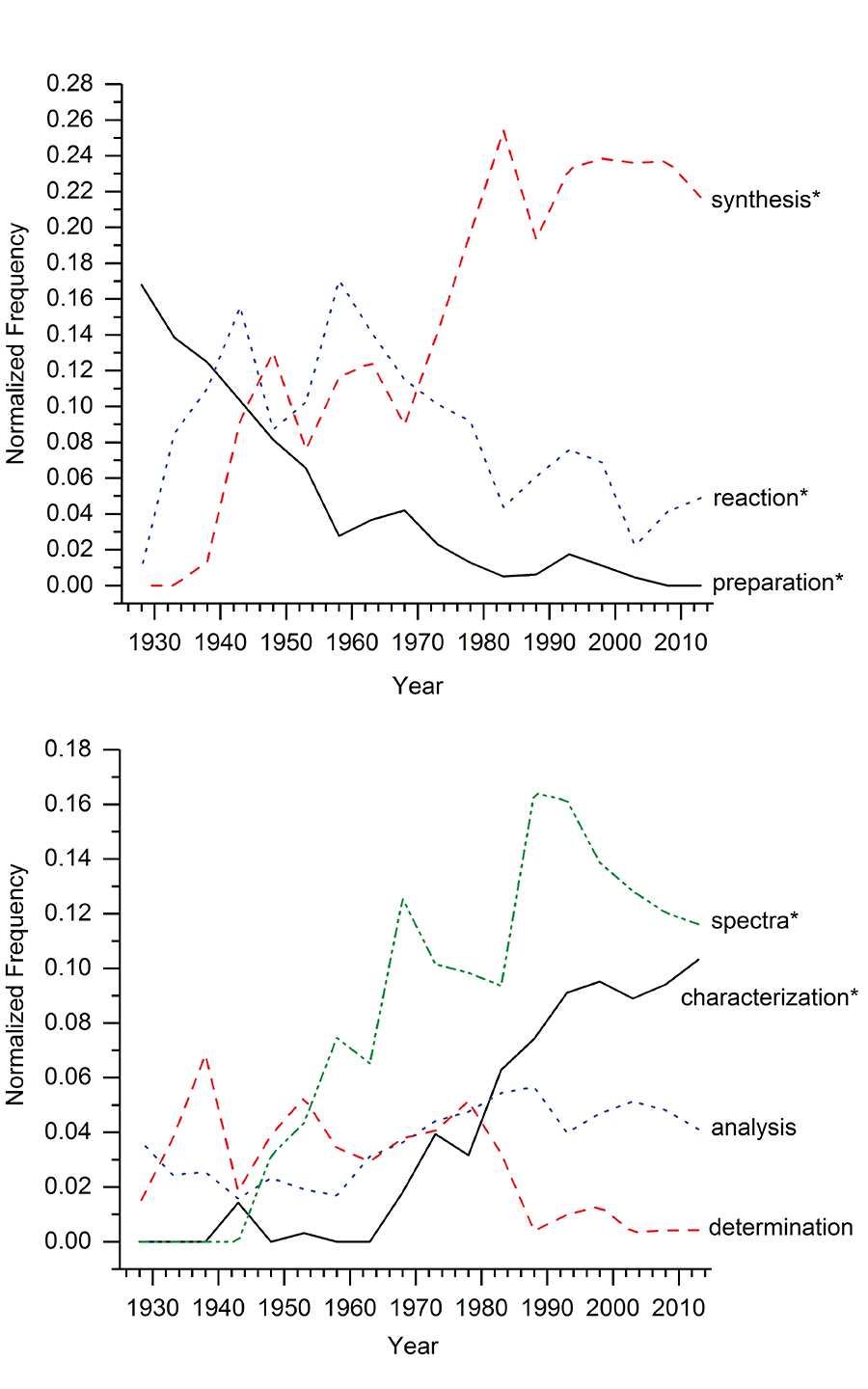
Figure 3. Frequency of selected words between 1925 and 2015. Asterisk indicates similar variations of the word were combined.
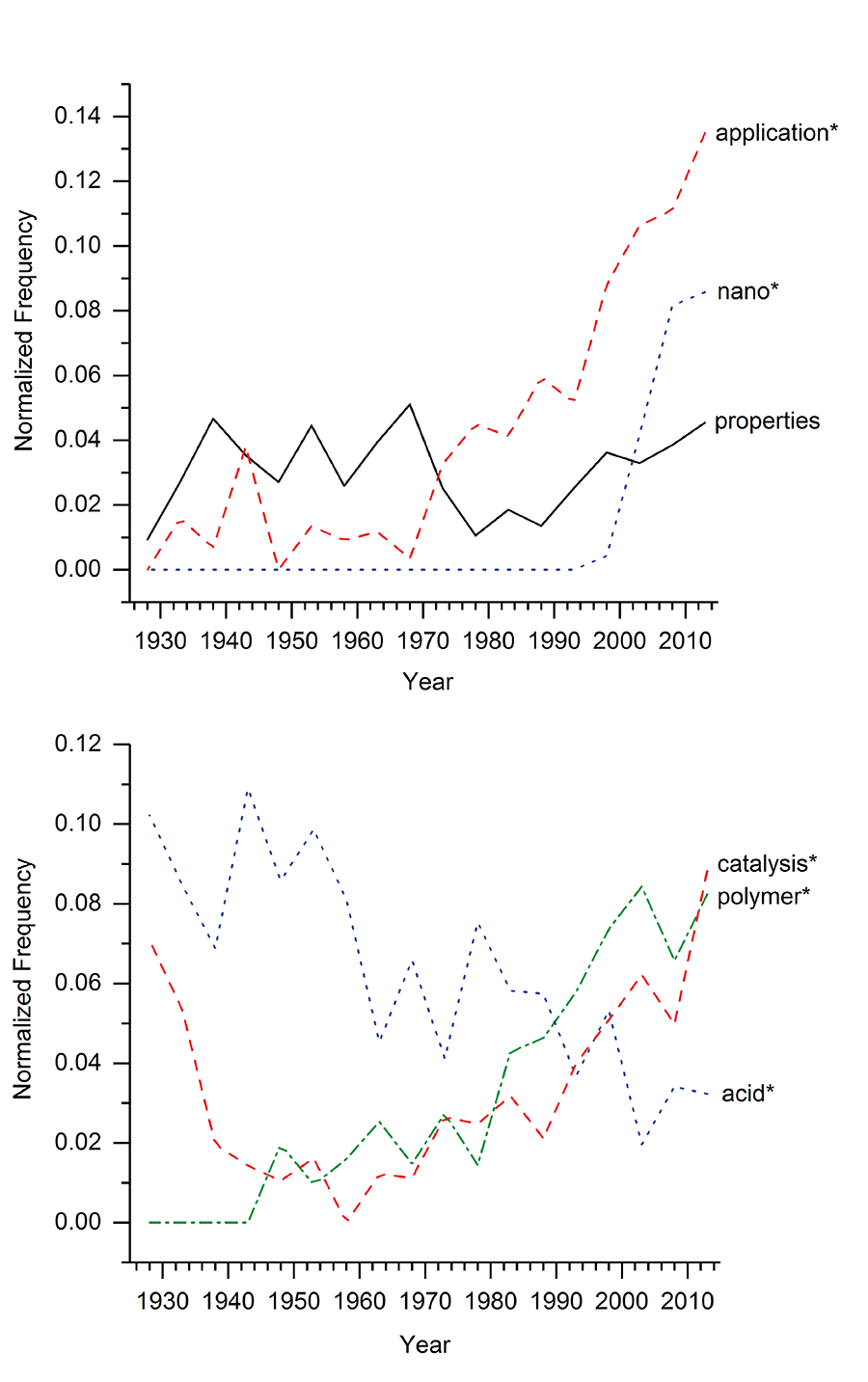
Figure 4. Frequency of selected words between 1925 and 2015. Asterisk indicates similar variations of the word were combined.
Text Analysis of Chemistry Thesis and Dissertations Titles - University Trends
A comparison of the top five title words by university from 1911 to 2015 is presented in Table 5.
Table 5. Five most common words (unigram) separated by university. Asterisk indicates similar variations of the word were combined.
| University | Years | Top 5 words from chemistry thesis and dissertation titles |
|---|---|---|
| Duke | 1928-2015 | synthesis*, reaction*, compound*, acid*, spectra* |
| Emory | 1923-2015 | synthesis*, reaction*, catalysis*, spectra*, application* |
| LSU | 1913-2014 | synthesis*, spectra*, reaction*, polymer*, metal* |
| UA | 1924-2015 | synthesis*, metal*, reaction*, application*, characterization* |
| UF | 1913-2015 | synthesis*, spectra*, application*, polymer*, reaction* |
| UGA | 1932-2015 | synthesis*, spectra*, chemistry, application*, characterization* |
| UK | 1914-2015 | synthesis*, reaction*, spectra*, acid*, analysis |
| UM | 1929-2015 | synthesis*, reaction*, chloride, preparation*, acid* |
| USC | 1911-2015 | synthesis*, spectra*, characterization*, complex*, structure |
Synthesis*, again, is the most popular title word used across all universities studied. Other popular words commonly appearing at multiple universities are reaction*, spectra*, acid*, and characterization*. The word application* was in the top five most commonly used words at UA, UF, and UGA. Polymer* was in the top five at LSU and UF, while metal* was only present in the top five at UA and LSU.
To conclude the text analysis, the author examined thesis and dissertation title words at UA over the past 15 years in an effort to observe recent trends at a particular university. The most common words were synthesis*, application*, catalysis*, and ionic. And the most popular bigram words revealed several unique research trends at UA over the past 15 years such as total synthesis, ionic liquids, palladium catalysis, and metal oxides (Table 6).
Readers interested in further text analysis of the nine ASERL university chemistry thesis and dissertation titles are encouraged to download the datasets and results from this article (see Appendix).
Table 6. Top four most common words (unigram and bigram) from The University of Alabama chemistry thesis and dissertation titles over the past 15 years.
| Rank | 2006-2010 | 2011-2015 | ||
|---|---|---|---|---|
| 1 | synthesis* | total, synthesis* | synthesis* | total, synthesis* |
| 2 | application* | ionic, liquids | metal* | metal*, oxide |
| 3 | catalysis* | palladium, catalysis* | application* | transition, metal* |
| 4 | ionic | thin, films | spectra* | mass, spectra* |
Summary of Research Trends
I began this study with the hypothesis that text analysis (term frequency) of chemistry thesis and dissertation titles can be used to understand chemistry research trends. The data and results here support the hypothesis of understanding research trends in chemistry at the nine ASERL institutions studied, albeit broadly. We can reach several research trend conclusions from the dataset outlined below:
- Overall, from 1911-2015, some of most common words found in chemistry thesis and dissertation titles were synthesis*, spectra*, reaction*, application*, complex*, and characterization*. We might therefore infer that such research areas are critical to the field of chemistry based on these results. These research trends were fairly consistent across universities for the overall dataset (i.e., 1900s to 2015). Analysis of bigram and trigram words across the entire dataset revealed commonly studied fields such as transition metal chemistry and organic total synthesis methods. Frequently used instrumental characterization techniques were observed such as Nuclear Magnetic Resonance (NMR) Spectroscopy and Gas Chromatography.
- Separating the data into historic era intervals and a yearly analysis of word frequency revealed how the use of a particular word, and presumably the related research, has changed over time. For example, in the early 1900s, preparation was favored over synthesis. Research on acids and creating derivatives of substances was common in the early to mid-1900s, while later there is a shift to spectroscopy/spectrometry, polymers, catalysis, and other areas (see Figures 3 and 4). This analysis assumed that the major word changes correspond to a change in research or development of new fields. There are some exceptions where the chemistry vocabulary changes and do not necessarily represent a change in research (e.g. preparation to synthesis). The broad nature of the data produces limitations and cautions with these assumptions.
- A look at the last 15 years of chemistry thesis and dissertation titles at UA revealed topics unique to the university including total synthesis, ionic liquids, palladium catalysis, thin films, and mass spectrometry.
The current text analysis of the thesis and dissertation title data appears to support the hypothesis of understanding research trends in chemistry, but only at a broad level.
Basic term frequency and more advanced co-word analysis studies are limited because of vocabulary changes, differing intended usage, and lack of sentence topical context (He 1999; Leydesdorff 1997; Milojevic et al. 2011).
Another consideration is that while chemistry journal article titles have a high relationship to the content within the article (Freeman and Dyson 1963; Freeman et al. 1964; Resnick 1961; Saracevic 1969; Tocatlian 1970; Windsor 1971), no information is reported on how relevant chemistry thesis and dissertation titles are to the content within them. As such, there is a possibility that the chemistry title words of thesis and dissertations are not representative of the content within. If this was demonstrated to be the case, it would disprove the hypothesis of this study.
Despite the broad nature of the extracted chemistry research trend data, there is still value in the data, particularly when comparing and analyzing thousands of thesis and dissertation titles. Programmatic approaches allow researchers to more easily analyze large datasets and compare data, which can be very difficult or impossible with manual techniques (Sugimoto et al. 2011). Future, more sophisticated programmatic approaches that can extract specific chemical information from thesis and dissertation titles or abstracts (Gurulingappa et al. 2013) and programmatically categorize them (Rafols and Leydesdorff 2009; Sugimoto et al. 2011; Zheng et al. 2006) into well-defined research topics (e.g., cooperative patent classification) could potentially support or disprove the hypothesis in this study.
Conclusions
The author analyzed 9,684 Chemistry thesis and dissertation titles from 1911-2015 via text analysis to extract the most frequent words and word pairs in an effort to understand chemistry research trends. The chemistry thesis and dissertation titles were collected from Duke University (Duke), Emory University (Emory), Louisiana State University (LSU), The University of Alabama (UA), University of Florida (UF), University of Georgia (UGA), University of Kentucky (UK), University of Mississippi (UM), and University of South Carolina (USC). Using custom scripts written in MATLAB and Mathematica, I found that some of the most common unigram words used included variants of synthesis, spectra, reaction, application, and complex. Popular bigram and trigram words included mass spectra, transition metal, total synthesis, nuclear magnetic resonance, and laser desorption ionization. I analyzed several selected commonly appearing words by their yearly frequency to understand word usage and research trends over time. Research on acids and creating derivatives of substances was popular in the early 1900s; research on spectra grew rapidly in the mid-1900s; and more recently, research on applications, nanomaterials, catalysis and polymers has increased. The appearance of a particular word or phrase presumably indicates research in the defined area. Many limitations become apparent upon analysis of the data, most importantly the broad nature of the data extracted. For example, the most commonly appearing word, synthesis, is not specific and can span nearly all chemical research areas. So while the data revealed broad research trends, its use beyond basic level research trends is problematic. Future work will need to focus on more advanced chemistry text analysis approaches that can programmatically categorize chemistry thesis and dissertations into highly specific subject areas. Such data may be useful for collection development and will advance efforts towards machine-assisted collections (Mitchell 2006).
Acknowledgements
I am grateful to Diana Y. Hartle (Science Librarian, University of Georgia) and Cristina M. Caminita (Head, Research & Instruction, Louisiana State University) for helping to provide thesis and dissertation bibliographic data. This project was funded by The University of Alabama and The University of Alabama Libraries.
Notes
1 The term "complex" is typically used to indicate the association of two or more entities (International Union of Pure and Applied Chemistry 2016). However, like the words "synthesis" and "preparation," "complex" is a very broad term and can indicate a large variety of research areas such as transition metal complexes or supramolecular polymer complexes (Cantrill 2015).
References
Banchs, R.E. 2013. Text Mining with Matlab. New York, NY: Springer.
Callon, M., Courtial, J.P. & Laville, F. 1991. Co-word analysis as a tool for describing the network of interactions between basic and technological research: The case of polymer chemistry. Scientometrics 22(1): 155-205. doi: 10.1007/bf02019280
Cantrill, S. 2015. 115 years of JACS titles [accessed April 27, 2017]. https://stuartcantrill.com/2015/06/02/115-years-of-jacs-titles/
Chrzastowski, T.E. 1991. Journal collection cost-effectiveness in an academic chemistry library: Results of a cost/use survey at the University of Illinois at Urbana-Champaign. Collection Management 14(1/2): 85-98. doi: 10.1300/J105v14n01_06
Danton, J.P. 1959. Doctoral study in librarianship in the United States. College & Research Libraries 20(6): 435-453. doi: 10.5860/crl_20_06_435
de Laet, A., Hehenkamp, J.J.J. & Wife, R.L. 2000. Finding drug candidates in virtual and lost/emerging chemistry. Journal of Heterocyclic Chemistry 37(3): 669-674. doi: 10.1002/jhet.5570370324
Downing, J., Harvey, M.J., Morgan, P.B., Murray-Rust, P., Rzepa, H.S., Stewart, D.C., Tonge, A.P. & Townsend, J.A. 2010. Spectra-t: Machine-based data extraction and semantic searching of chemistry e-theses. Journal of Chemical Information and Modeling 50(2): 251-261. doi: 10.1021/ci9003688
Finch, J.L. & Flenner, A.R. 2016. Using data visualization to examine an academic library collection. College & Research Libraries 77: 765-778. doi: 10.5860/crl.77.6.765
Finlay, C.S., Sugimoto, C.R., Daifeng Li & Russell, T.G. 2012. LIS dissertation titles and abstracts (1930-2009): Where have all the librar* gone? Library Quarterly 82(1): 29-46. doi: 10.1086/662945
Freeman, R.R. & Dyson, G.M. 1963. Development and production of Chemical Titles, a current awareness index publication prepared with the aid of a computer. Journal of Chemical Documentation 3(1): 16-20. doi: 10.1021/c160008a007
Freeman, R.R., Godfrey, J.T., Maizell, R.E., Rice, C.N. & Shepherd, W.H. 1964. Automatic preparation of selected title lists for current awareness services and as annual summaries. Journal of Chemical Documentation 4(2): 107-112. doi: 10.1021/c160013a010
Gooden, A.M. 2001. Citation analysis of chemistry doctoral dissertations: An Ohio State University case study. Issues in Science & Technology Librarianship 32(Fall 2001). doi: 10.5062/F40P0X05
Gurulingappa, H., Mudi, A., Toldo, L., Hofmann-Apitius, M. & Bhate, J. 2013. Challenges in mining the literature for chemical information. RSC Advances 3(37): 16194-16211. doi: 10.1039/C3RA40787J
Haren, S.M. 2014. Data visualization as a tool for collection assessment: Mapping the Latin American studies collection at University of California, Riverside. Library Collections Acquisitions & Technical Services 38(3-4): 70-81. doi: 10.1080/14649055.2015.1059219
He, Q. 1999. Knowledge discovery through co-word analysis. Library Trends 48(1): 133-159.
Hoffmann, K. & Doucette, L. 2012. A review of citation analysis methodologies for collection management. College & Research Libraries 73(4): 321-335. doi: 10.5860/crl-254
International Union of Pure and Applied Chemistry. IUPAC Gold Book. 2016. [accessed November 23, 2016]. https://goldbook.iupac.org/
Jamali, H.R. & Nikzad, M. 2011. Article title type and its relation with the number of downloads and citations. Scientometrics 88(2): 653-661. doi: 10.1007/s11192-011-0412-z
Keller, B. 1992. Subject content through title: A masters theses matching study at Indiana State University. Cataloging & Classification Quarterly 15(3): 69-80. doi: 10.1300/J104v15n03_05
Letchford, A., Moat, H.S. & Preis, T. 2015. The advantage of short paper titles. Royal Society Open Science 2(8): 1-6. doi: 10.1098/rsos.150266
Leydesdorff, L. 1997. Why words and co-words cannot map the development of the sciences. Journal of the American Society for Information Science 48(5): 418-427. doi: 10.1002/(SICI)1097-4571(199705)48:5<418::AID-ASI4>3.0.CO;2-Y
Link, F.E., Tosaka, Y. & Weng, C. 2015. Mining and analyzing circulation and ILL data for informed collection development. College & Research Libraries 76(6): 740-755. doi: 10.5860/crl.76.6.740
Loomis, M.E. 1985. Emerging content in nursing: An analysis of dissertation abstracts and titles: 1976-1982. Nursing Research 34(2): 113-119.
Maiti, D.C. & Dutta, B. 2013. Comparative study between words in titles and keywords of some articles on knowledge organisation. DESIDOC Journal of Library & Information Technology 33(6): 498-508.
Milojevic, S., Sugimoto, C.R., Yan, E. & Ding, Y. 2011. The cognitive structure of library and information science: Analysis of article title words. Journal of the American Society for Information Science and Technology 62(10): 1933-1953. doi: 10.1002/asi.21602
Mitchell, S. 2006. Machine assistance in collection building: New tools, research, issues, and reflections. Information Technology & Libraries 25(4): 190-216. doi: 10.6017/ital.v25i4.3353
Murphy, S.A. 2015. How data visualization supports academic library assessment. College & Research Libraries News 76(9): 482-486. http://crln.acrl.org/index.php/crlnews/article/view/9379/10545
Nagarkar, S.P. & Kumbhar, R. 2015. Text mining. Library Review 64(3): 248-262. doi: 10.1108/LR-08-2014-0091
Newberry, W.F. 1978. Subject perspective of library science dissertations. Journal of Education for Librarianship 18(3): 203-212. doi: 10.2307/40322549
Porter, M. 2006. The Porter stemming algorithm [accessed June 25, 2016]. https://tartarus.org/martin/PorterStemmer/
Rafols, I. & Leydesdorff, L. 2009. Content-based and algorithmic classifications of journals: Perspectives on the dynamics of scientific communication and indexer effects. Journal of the American Society for Information Science and Technology 60(9): 1823-1835. doi: 10.1002/asi.21086
Resnick, A. 1961. Relative effectiveness of document titles and abstracts for determining relevance of documents. Science 134(3484): 1004-1006. doi: 10.1126/science.134.3484.1004
Rodriguez, K. & Moreiro, J.A. 1996. The growth and development of research in the field of ecology - as measured by dissertation title analysis. Scientometrics 35(1): 59-70. doi: 10.1007/bf02018233
Saracevic, T. 1969. Comparative effects of titles, abstracts and full text on relevance judgments. Proceedings of the American Society for Information Science 6:(293-299.
Siguenza-Guzman, L., Saquicela, V., Avila-Ordóñez, E., Vandewalle, J. & Cattrysse, D. 2015. Literature review of data mining applications in academic libraries. Journal of Academic Librarianship 41(4): 499-510. doi: 10.1016/j.acalib.2015.06.007
Stoye, E. 2015. Forgotten synthetic PhD theses set to be given new lease of life [accessed June 26, 2016]. http://www.rsc.org/chemistryworld/2015/03/forgotten-synthetic-phd-theses-set-be-given-new-lease-life
Sudhier, K.G.P. & Kumar, V.D. 2010. Scientometric study of doctoral dissertations in biochemistry in the University of Kerala, India. Library Philosophy and Practice: 1-16. http://digitalcommons.unl.edu/cgi/viewcontent.cgi?article=1411&context=libphilprac
Sugimoto, C.R., Li, D., Russell, T.G., Finlay, S.C. & Ding, Y. 2011. The shifting sands of disciplinary development: Analyzing North American library and information science dissertations using latent Dirichlet allocation. Journal of the American Society for Information Science & Technology 62(1): 185-204. doi: 10.1002/asi.21435
Thomson Reuters. 2016. Thomson Reuters Endnote connection files [accessed June 25, 2016]. http://endnote.com/downloads/connections
Tocatlian, J.J. 1970. Are titles of chemical papers becoming more informative? Journal of the American Society for Information Science 21(5): 345-350. doi: 10.1002/asi.4630210506
Vallmitjana, N. & Sabaté, L.G. 2008. Citation analysis of Ph.D. Dissertation references as a tool for collection management in an academic chemistry library. College & Research Libraries 69(1): 72-81. doi: 10.5860/crl.69.1.72
Whitesides, G.M. 2015. Reinventing chemistry. Angewandte Chemie International Edition 54(11): 3196-3209. doi: 10.1002/anie.201410884
Wical, S.H. & Vandenbark, R.T. 2015. Combining citation studies and usage statistics to build a stronger collection. Library Resources & Technical Services 59(1): 33-42. doi: 10.5860/lrts.59n1.33
Windsor, D.A. 1971. The frequency of titles containing "dopa-words" in a complete collection of published documents on dopa (3,4-dihydroxyphenylalanine). Journal of Chemical Documentation 11(4): 227-228. doi: 10.1021/c160043a011
Xie, S., Zhang, J. & Ho, Y.-S. 2008. Assessment of world aerosol research trends by bibliometric analysis. Scientometrics 77(1): 113-130. doi: 10.1007/s11192-007-1928-0
Zhang, L. 2013. A comparison of the citation patterns of doctoral students in chemistry versus chemical engineering at Mississippi State University, 2002–2011. Science & Technology Libraries 32(3): 299-313. doi: 10.1080/0194262X.2013.791169
Zheng, B., McLean, D.C. & Lu, X. 2006. Identifying biological concepts from a protein-related corpus with a probabilistic topic model. BMC Bioinformatics 7(1): 1-10. doi: 10.1186/1471-2105-7-58
Appendix
The appendix is available as a Word file
| Previous | Contents | Next |

This work is licensed under a Creative Commons Attribution 4.0 International License.
